摘要: 针对模糊贝叶斯网络中先验概率输入的不确定性问题,通过证据理论对专家意见进行融合,得到更加可靠的先验概率。同时,提出一种证据理论的改进方法,解决证据理论不能处理高冲突数据的问题,从而降低专家意见的融合冲突,使专家意见可以合理且充分地融合。最后,通过人类可信性分析的相关实例验证理论的合理性,并通过与不同方法对比,说明所提融合方法的可行性和优势。
关键词: 改进证据理论; 贝叶斯网络; 数据融合; 风险分析
论文《基于改进证据理论的模糊贝叶斯网络及其应用》发表在《新疆大学学报(自然科学版中英文)》,版权归《新疆大学学报(自然科学版中英文)》所有。本文来自网络平台,仅供参考。
0 引言
不确定性是现实世界普遍存在的现象,截至目前,人们提出了多种数学模型来表示不确定性,如概率论[1]、Dempster-Shafer证据理论[2]、模糊数学[3]等。一方面,概率随机性理论是研究和处理事件是否发生的不确定性问题的理论基础;另一方面,模糊理论是研究和处理事件概念边界不确定性问题的理论基础。所以将随机理论和模糊理论相结合,可以用来研究和处理具有这两种混合不确定性属性的问题。例如,Zadeh[4]将模糊集的概率定义为其隶属函数的期望;Khalili[5]研究了模糊事件之间的独立性;Smets[6]引入了模糊事件条件概率的概念;Baldwin等[7]讨论了连续域模糊子集的条件概率问题;Lee等[8]基于Zadeh的模糊事件概率测度概念确定了一组新型模糊数。
随着模糊随机理论的发展,模糊理论被一些学者应用到贝叶斯分析中。Martz等[9]就这一主题发表的专著为模糊贝叶斯可靠性分析提供了一种研究途径。此后,一些研究者在此基础上研究模糊集理论在可靠性分析中的应用。Onisawa等[10]给出了许多不同的模糊可靠性方法。Cho[11]、Wang[12]、Wu[13]等也采用模糊概率、语言变量和模糊逻辑方法,研究可靠性模型和风险评估。
此外,诸多学者将上述理论与贝叶斯网络(Bayesian Network, BN)相结合,构建模糊贝叶斯网络(Fuzzy Bayesian Network, FBN)。贝叶斯网络是模拟人类推理中基于概率因果关系的有效模型,所以确定一个领域的因果结构在许多情况下都是一个关键问题。贝叶斯网络的拓扑结构为有向无环图(Directed Acyclic Graph, DAG),且有向无环图中的节点表示随机变量,若两个节点相连,则说明两个节点之间存在因果关系。在贝叶斯网络中,每个节点状态的划分往往是模糊的,而且它们的概率有着一定的不确定性,故将模糊集引入贝叶斯网络中,可以更好地解释这种不确定性。陆莹等[14]将模糊理论与贝叶斯网络相结合,应用于地铁火灾风险预测。Zhang等[15]将模糊贝叶斯网络应用于管道损伤安全风险分析。针对模糊贝叶斯网络先验概率的输入不确定性问题,Pan等[16]在文献[15]的基础上,将 DS证据理论应用到模糊贝叶斯网络中,但证据理论本身在数据融合方面存在一些缺陷,所以需要对其进行改进和修正。
证据理论自 20 世纪 60 年代由 Dempster提出集值映射的概念并定义上、下概率以来,经过多年发展,已成为处理不确定性问题的重要工具。20 世纪 70 年代,Shafer进一步发展了这一理论,提出信任函数的概念,并创立了“证据的数学理论”[2]。近年来,证据理论的研究主要集中在以下几个方面:基本概率分配函数的获取方法、证据预处理以及改进合成规则。例如,Kushwah等[17]提出了一种基于时态的证据理论多传感器融合方法,用于室内活动识别,该方法在证据理论框架内开发了一种增量冲突解决方法,并引入时间信息以提高融合效果。陆文星等[18]通过引入证据距离来确定证据源的客观权重,从而提高证据理论的融合水平。尹东亮等[19]将云模型与证据理论有效结合在一起,提出一种新的目标决策方法。
受上述文献启发,本文先通过引入评价系统对证据理论进行改进,解决其不能有效处理高冲突证据的缺陷;然后,将改进的证据理论与模糊贝叶斯网络结合起来,进一步提升模糊贝叶斯网络在正向推理过程中的准确性;最后,将基于改进证据理论的模糊贝叶斯网络应用于人类可信性分析[20],更好地解释分析过程中那些不确定性数据。
1 基础知识
1.1 模糊集
设 $Omega$ 为论域,函数 $ ilde{A}:Omega
ightarrow[0,1]$ 称为 $Omega$ 的模糊子集[4]。对于 $xinOmega$,区间 $[0,1]$ 内的实数 $ ilde{A}(x)$ 称为 $x$ 在 $ ilde{A}$ 中的隶属度,表示命题“$x$ 属于 $ ilde{A}$”的程度。
1.2 贝叶斯网络
贝叶斯网络又称信念网络,是对贝叶斯定理的扩展,也是不确定信息表示和推理最有效的理论模型之一。贝叶斯网络是由节点和有向弧组成的有向无环图。节点表示变量,节点之间的弧线表示对应变量之间的关系。没有父节点的节点称为根节点,其只具有先验概率。所有非根节点都具有条件概率表,该表包含节点每个状态在其父节点所有状态组合条件下的概率。非根节点中没有后代的节点称为叶节点[22]。贝叶斯网络基于定义良好的贝叶斯规则。下面是条件概率公式和贝叶斯公式。
1.3 模糊贝叶斯网络
1.3.1 模糊贝叶斯公式
由于贝叶斯网络各节点的精确概率难以得到,本文用三角模糊数代替传统的精确概率。贝叶斯规则规定了学习系统在新数据到达时应该如何更新其信念。边缘化原则提供了根据现有概率来推导新命题的概率。同时,在上述模糊概率上利用式(2)的四则运算,可以对模糊贝叶斯规则进行细化,以支持模糊贝叶斯网络模型中的模糊贝叶斯推理[15],细化结果如式$(6)sim(9)$所示:
式(6)说明了模糊条件独立性,式(7)说明了模糊联合概率,式(8)说明了模糊边缘化规则,式(9)说明了模糊贝叶斯规则。
1.3.2 模糊贝叶斯网络结构的条件独立性
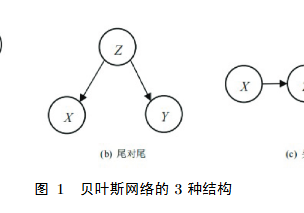
若随机变量 $X$ 和 $Y$ 满足 $P(X, Y)=P(X)otimes P(Y)$,则称 $X$ 和 $Y$ 是独立的。因此,可以根据贝叶斯网络的3种结构分别讨论其结构的独立性。
1) 头对头。如图 1(a)所示,可知 $Z$ 中包含的信息能由 $X$ 和 $Y$ 推出。所以由式(6)可得
$$P(X, Y, Z)=P(X)otimes P(Y)otimes P(Zmid X, Y),(10)$$
又
$$P(X, Y, Z)=P(X, Y)otimes P(Zmid X, Y),(11)$$
化简后得到 $P(X, Y)=P(X)otimes P(Y)$,所以在 $Z$ 未知的情况下,$X$ 和 $Y$ 是被阻断的,称之为头对头条件独立。
2) 尾对尾。如图 1(b)所示,$X$ 和 $Y$ 所包含信息可以由 $Z$ 推出,但需要考虑 $Z$ 已知和 $Z$ 未知两种情况。
(i) 当 $Z$ 未知时。有 $P(X, Y, Z)=P(Z)otimes P(Xmid Z)otimes P(Ymid Z)$,此时无法得出
$$P(X, Y)=P(X)otimes P(Y),(12)$$
即 $Z$ 未知时,$X$ 和 $Y$ 不独立。
(ii) 当 $Z$ 已知时。有 $P(X, Ymid Z)=P(X, Y, Z)oslash P(Z)$,利用
$$P(X, Y, Z)=P(Z)otimes P(Xmid Z)otimes P(Ymid Z),(13)$$
化简可得
$$�egin{align*} P(X, Ymid Z)&=P(X, Y, Z)oslash P(Z)\
&=P(Z)otimes P(Xmid Z)otimes P(Ymid Z)oslash P(Z)\
&=P(Xmid Z)otimes P(Ymid Z),end{align*}qquad(14)$$
所以 $Z$ 已知时,$X$ 和 $Y$ 是被阻断的,称为尾对尾独立。
3) 头对尾。如图 1(c)所示,$Y$ 所包含信息可以由 $Z$ 推出,$Z$ 所包含信息可以由 $X$ 推出,但需要考虑 $Z$ 已知和 $Z$ 未知两种情况。
(i) 当 $Z$ 未知时。有 $P(X, Y, Z)=P(X)otimes P(Zmid X)otimes P(Ymid Z)$,但无法推出
$$P(X, Y)=P(X)otimes P(Y),(15)$$
即 $Z$ 未知时,$X$ 和 $Y$ 不独立。
(ii) 当 $Z$ 已知时。有 $P(X, Ymid Z)=P(X, Y, Z)oslash P(Z)$,且根据
$$P(X, Y)=P(X)otimes P(Zmid X)=P(Z)otimes P(Xmid Z),(16)$$
化简可得
$$�egin{align*} P(X, Ymid Z)&=P(X, Y, Z)oslash P(Z)\
&=P(X)otimes P(Zmid X)otimes P(Ymid Z)oslash P(Z)\
&=P(X, Z)otimes P(Ymid Z)oslash P(Z)\
&=P(Xmid Z)otimes P(Ymid Z),end{align*}qquad(17)$$
所以 $Z$ 已知时,$X$ 和 $Y$ 是被阻断的,称为头对尾独立。
2 基于改进的证据理论的模糊贝叶斯网络
模糊贝叶斯网络的边缘概率可通过两种方法得到,其一是通过大量数据来计算边缘概率,其二是通过专家意见来得到边缘概率。本文采用第二种方法,所以需要对已知的专家意见进行融合。证据理论是常用的数据融合方法,可以融合不同专家或数据源的知识和信息,从而更好体现问题的未知性和不确定性。但证据理论具有一个明显的缺点,极端冲突数据的融合结果是不可接受的,故需要针对数据的极端冲突对证据理论进行改进。
2.1 证据理论基础
证据理论是一种推理和决策方法,通过量化相信程度来处理决策中不确定性和模糊性问题。
设 $Theta=left{ heta_1, heta_2,cdots, heta_N
ight}$ 是一个论域,且其元素个数有限,则称 $Theta$ 为识别框架,那么 $Theta$ 所有子集组成的集合称为 $Theta$ 的幂集[16],记作 $2^{Theta}$。若映射 $m: 2^{Theta}
ightarrow[0,1]$ 满足
$$left{�egin{array}{l} m(varnothing)=0,\ sum_{AsubsetTheta} m(A)=1,end{array}
ight.qquad(18)$$
式中: $varnothing$ 为空集; $A$ 为 $Theta$ 的任意子集,则称 $m$ 为基本概率分配函数[16]。设 $m_1, m_2,cdots, m_n$ 是识别框架 $Theta$ 中 $n$ 组独立的基本概率分配函数,$A_1, A_2,cdots, A_k$ 是识别框架 $Theta$ 的 $k$ 组子集,利用证据理论进行证据融合,可表达为
$$m(A)=frac{sum_{A_icap A_jcapcdotscap A_k=A} m_1left(A_i
ight) m_2left(A_j
ight)cdots m_nleft(A_k
ight)}{1-K},(19)$$
式中: $K$ 为各证据之间的冲突系数,表示证据之间的冲突程度[16],形式如下:
$$K=sum_{A_icap A_jcapcdotscap A_k=varnothing} m_1left(A_i
ight) m_2left(A_j
ight)cdots m_nleft(A_k
ight).qquad(20)$$
实际生活中,存在 $5\%$ 的测量误差是可以被接受的,并且在统计学中,常用 $5\%$ 作为假设检验中的显著性水平,所以本文将 $K$ 的阈值设为 0.95。可根据情况,做如下讨论。
1) 若 $K<0.95$,证据之间的冲突可以被接受,则按经典证据理论由式(19)(20)进行证据融合。
2) 若 $Kgeq 0.95$,证据之间的冲突不可以被接受,则使用 2.2 节的改进证据理论。
2.2 改进的证据理论
2.2.1 模糊数据的证据理论计算方法
在介绍改进证据理论前,本文先定义针对模糊数据的证据理论计算方法。出于降低计算复杂度的目的,将三角模糊数视为三维数组对其进行计算,下面是具体计算步骤。
设 $ ilde{m}_1, ilde{m}_2,cdots, ilde{m}_n$ 是识别框架 $Theta$ 中 $n$ 组独立的基本概率分配函数,$A_1, A_2,cdots, A_k$ 是识别框架 $Theta$ 的 $k$ 组子集,且 $ ilde{m}_ileft(A_j
ight)=left(a_{i j}, b_{i j}, c_{i j}
ight), i=1,cdots, n, j=1,cdots, k$ 是一个三角模糊数。融合前需对其进行归一化
$$ ilde{M}_ileft(A_j
ight)=left(frac{a_{i j}}{sum_{j=1}^k a_{i j}},frac{b_{i j}}{sum_{j=1}^k b_{i j}},frac{c_{i j}}{sum_{j=1}^k c_{i j}}
ight),quad(21)$$
然后利用证据理论进行证据融合得到 $ ilde{M}(A)$,最后将其转化成模糊数的形式 $ ilde{m}(A)$
$$left{�egin{array}{l} ilde{M}(A)=frac{sum_{A_icap A_jcapcdotscap A_k=A} ilde{M}_1left(A_i
ight) ilde{M}_2left(A_j
ight)cdots ilde{M}_nleft(A_k
ight)}{(1,1,1)-K},\ ilde{m}(A)= ilde{M}(A)otimesfrac{1}{n}sum_{i=1}^nsum_{j=1}^kleft(a_{i j}, b_{i j}, c_{i j}
ight),end{array}
ight.$$
其中
$$K=sum_{A_icap A_jcapcdotscap A_k=varnothing} ilde{M}_1left(A_i
ight) ilde{M}_2left(A_j
ight)cdots ilde{M}_nleft(A_k
ight).(23)$$
2.2.2 改进的证据理论
为减少证据过高冲突带来的负面影响,本文引入评价系统来弱化冲突系数。专家之间的信任程度决定了冲突系数的可靠性。当专家之间的信任程度较低时,也会导致其提供的证据冲突更高。引入专家之间的相互评价,可以在一定程度上避免冲突系数过高的情况。
评价系统由专家之间的主观评价和客观评价构成。主观评价由每个专家根据其他专家的经历与成就对其打分得到,客观评价由不同专家所提供的基本概率分配函数得到,在二者的共同作用下,基本概率分配函数向着对方偏移,从而改变原有的基本概率分配函数,达到降低冲突系数的目的。
主观评价由专家根据对方的简历以及相关成就得出。例如,专家 $e_i$ 对专家 $e_j$ 的主观评价为 $s u b_{i j}, i, j=1,2,cdots, n$。客观评价先计算证据 $m_i(i=1,2,cdots, n)$ 与证据 $m_j(j=1,2,cdots, n)$ 之间的距离,再求出他们的相似度,根据相似度计算每位专家所得的客观评价 $o b_i(i=1,2,cdots, n)$,即
$$left{�egin{align*} d_{i j}&=sqrt{sum_{r=1}^kleft[m_ileft(A_r
ight)-m_jleft(A_r
ight)
ight]^2},\ o b_{i j}&=1-d_{i j}.end{align*}
ight.qquad(24)$$
若冲突系数 $Kgeq 0.95$,则可以将这组数据视为异见数据,需要通过评价系统对数据进行修正,让专家的基本信任分配函数向着对方偏移。先由专家 $e_i$ 根据已知信息得出对专家 $e_j$ 的主观评价 $s u b_{i j}$,再根据基本概率分配函数得出客观评价,然后将主、客观评价作为偏移的权重,对基本信任函数进行修正。由于主观评价是由一名专家对其他专家的主观判断给出,可能存在一定偏差,所以对基本信任函数进行修正时,应适当降低主观评价的权重。因此,本文采取的主、客观权重比为 $1: n-1$,其中 $n$ 为专家个数。当只有两名专家时,为有效降低主观评价权重,令主、客观权重比为 1:2。由于本文采用的例子以及给出的伪代码均以三名专家为例,故后续所用权重比为 1:2。
设专家 $e_i$ 对证据焦元 $A_r$ 的初始基本概率分配函数为 $m_ileft(A_r
ight)$,将主、客观评价按 $1: 2$ 赋权求和后,再经过归一化得到新的基本概率分配函数 $m_i^{prime}left(A_r
ight)$,即
$$m_i^{prime}left(A_r
ight)=frac{sum_{j=1}^nleft(frac{1}{3} s u b_{i j}+frac{2}{3} o b_{i j}
ight) m_jleft(A_r
ight)}{sum_{r=1}^kleft[sum_{j=1}^nleft(frac{1}{3} s u b_{i j}+frac{2}{3} o b_{i j}
ight) m_jleft(A_r
ight)
ight]},(25)$$
此时,显然有
$$left{�egin{array}{l}sum_{r=1}^k m_i^{prime}left(A_r
ight)=1,\ m(varnothing)=0,end{array}
ight.qquad(26)$$
满足式(18)中基本概率分配函数的定义。因此,可由式(27)计算新的证据冲突系数 $K^{prime}$ 如下:
$$K^{prime}=sum_{A_icap A_jcapcdotscap A_k=varnothing} m_1^{prime}left(A_i
ight) m_2^{prime}left(A_j
ight)cdots m_n^{prime}left(A_k
ight),qquad(27)$$
再判断 $K^{prime}$ 是否小于 0.95。若小于 0.95,则用式(28)进行证据融合;否则,将得到的基本概率分配函数再次带入式$(24)sim(25)、(27)$,计算新的 $K^{prime}$,直至 $K^{prime}<0.95$ 时,再用式(28)进行证据融合,即
$$m^{prime}(A)=frac{sum_{A_icap A_jcapcdotscap A_k=A} m_1^{prime}left(A_i
ight) m_2^{prime}left(A_j
ight)cdots m_n^{prime}left(A_k
ight)}{1-K^{prime}}.(28)$$
由于式(25)是对基本概率分配函数进行修正,所以还会出现一种特殊情况,即多次偏移后导致 $K^{prime}$ 不再缩小,本文将这种情况记为收敛。因此,当 $K^{prime}>0.95$ 且收敛时,也利用式(28)进行融合。
改进证据理论的详细程序如算法 1 所示,基于改进证据理论的模糊贝叶斯网络的建模流程如图 2 所示。
在模糊集中,用一个相对最好的精确数来表示模糊数的过程,被称为去模糊化。去模糊化的方法有平均面积法、加权平均法、最大隶属度法、重力法等多种形式。在上述模糊贝叶斯网络中,每个节点的计算结果均用三角模糊数表示,本文使用平均面积法把模糊概率转化为精确概率[23],计算方法如下:
$$P_{ ext{fuzzy}}(X)=(a, b, c),quad P_{ ext{accurate}}(X)=frac{a+2 b+c}{4}.qquad(29)$$
算法1 改进证据理论算法
```
Input 三个专家对一个因素的风险评价 M = [m₁, m₂, m₃]^T,以及专家之间的相互评价矩阵 S = [sub_ij],其中 i, j = 1,2,3
Step 1 计算矩阵 R₁ = kron(m₃, m₁.T × m₂) // 计算三个专家证据的克罗内克积,得到 m₁(A_i)m₂(A_j)m₃(A_k)
Step 2 计算矩阵 R₂ = diag(m₁.T × m₂).T × m₃ // 通过 (m₁.T × m₂).T 的对角线元素得到 A_i∩A_j∩A_k≠∅ 时的 m₁(A_i)m₂(A_j)m₃(A_k) 矩阵
Step 3 计算冲突系数 K = sum(R₁) - sum(diag(R₂))
Step 4 If K < 0.95:
融合结果 m = diag(R₂) / (1-K)
Else:
While K > 0.95:
计算相似度矩阵 O = [ob_ij],其中 ob_ij = 1 - ||m_i - m_j||_2
计算意见偏移矩阵 R₃ = (S + 2O) / 3
更新专家意见 M = R₃ × M = [m₁, m₂, m₃]
重复 Step 1 ~ Step 4
If M 收敛:
Break
融合结果 m = diag(R₂) / (1-K)
Output 输出结果 m、K。
```
3 人类可信性分析
人的可信性分析作为大规模复杂系统概率安全评估的重要组成部分,旨在量化人对给定任务系统风险的贡献程度。人的可信性分析中,依赖性评估的目的是量化一个任务失败对后续任务失败概率的影响。如果两个任务之间存在依赖关系,且前一个任务失败,则后续任务失败的概率更高。如果上述任务失败,依赖性评估的结果为条件人为错误概率。人为错误率预测技术是一种具有代表性和常用的方法。人为错误率预测技术中,往往先给出一些影响因素和其 5 个依赖水平,再根据建议的因素来评价两个任务之间的依赖关系。基于人为错误率预测技术已经提出了许多方法[20]。
为进一步说明该方法的具体过程并证明其有效性,本文采用文献[20]中核电厂启动后人因故障事件的案例来研究前后两次故障之间的依赖关系。两个任务之间的依赖关系可以用总体依赖程度(Overall Dependence Level, ODL)来表示。通过前人工作和专家经验可以得出直接影响最终总体依赖程度的因素有 3 个,分别是时间接近性(Closeness in Time, CT)、任务相关性(Task Relatedness, TR)、执行者相似性(Similarity of Performers, SP)。此外,任务相关性受线索相似性(Similarity of Cues, SC)和目标相似性(Similarity of Goals, SG)两个因素影响。根据上述5个因素的因果关系,可以得出如图 3 所示的模糊贝叶斯网络结构[20]。并根据经验将每个根节点分成 I、 II、 III、IV、 V 评价等级,等级越高说明对应属性的相似性越高,每个因素的具体等级划分如表 1~4 所示。针对本文数据而言,其叶节点的条件概率只有 0 或 1 这两种可能:
$$P(TR=I|SC=I, SG=I)=1,qquad(30)$$
$$�egin{align*} P(TR=IImid SC=I,,SG=I)=&,P(TR=IIImid SC=I,,SG=I)\
=&,P(TR=IVmid SC=I,,SG=I)\
=&,P(TR=Vmid SC=I,,SG=I)\
=&,0,end{align*}qquad(31)$$
记 $p_i(i=1,2,cdots, 5)$ 为 5 维标准单位向量,则 $TR$ 在 $SC$、$SG$ 都为 I 等级条件下的概率记为 $p_1=(1,0,0,0,0)$。同理,可以得到如表5、表6所示的条件概率。
现有三位专家 $e_1、 e_2、 e_3$,对每个根节点评价等级进行打分,且分值的取值范围为 1~10 之间的整数,分值越高说明其越有可能发生。再根据表 7 将分值转化为模糊概率。他们对 4 个根节点的看法 $m_1、 m_2、 m_3$ 如表 8 所示,他们之间的相互评价如表9所示。
表1 CT的等级划分
| 关键锚点 | 等级判断 |
| 时间差小于5分钟 | V |
| 时间差小于 20分钟 | IV |
| 时间差小于 30分钟 | III |
| 时间差小于 1小时 | II |
| 时间差大于8小时 | I |
表2 SP的等级划分
| 关键锚点 | 等级判断 |
| 同一个人 | V |
| 同一个团队 | IV |
| 拥有相同条件的不同人 | III |
| 不同团队 | II |
| 没有相同条件的不同人 | I |
表3 SC的等级划分
| 关键锚点 | 等级判断 |
| 任务在相同条件下 | V |
| 有大部分的相似因素 | IV |
| 有中等多的相似因素 | III |
| 有少部分的相似因素 | II |
| 没有相似因素 | I |
表4 SG的等级划分
| 关键锚点 | 等级判断 |
| 近乎相同的目标 | V |
| 目标相似性较高 | IV |
| 目标相似性一般 | III |
| 目标相似性较弱 | II |
| 目标没有相似性 | I |
表5 TR的条件概率
| SCSG | I | II | III | IV | V |
| I | p₁ | p₁ | p₂ | p₂ | p₃ |
| II | p₂ | p₂ | p₂ | p₃ | p₃ |
| III | p₂ | p₂ | p₂ | p₃ | p₄ |
| IV | p₃ | p₃ | p₃ | p₄ | p₄ |
| V | p₄ | p₄ | p₄ | p₅ | p₅ |
表6 ODL的条件概率(此处为示例,完整表见原文)
*(注:原文中表6结构复杂,此处以示意为主。)*
表7 各分值对应的模糊概率
| 评价标准 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 下界 | 0.00 | 0.05 | 0.15 | 0.25 | 0.35 | 0.45 | 0.55 | 0.65 | 0.75 | 0.85 |
| 中间 | 0.00 | 0.10 | 0.20 | 0.30 | 0.40 | 0.50 | 0.60 | 0.70 | 0.80 | 0.90 |
| 上界 | 0.05 | 0.15 | 0.25 | 0.35 | 0.45 | 0.55 | 0.65 | 0.75 | 0.85 | 1.00 |
表8 专家意见 (示例:SP节点)
| 专家 | I | II | III | IV | V |
| m₁ | (0.00,0.00,0.05) | (0.00,0.00,0.05) | (0.15,0.20,0.25) | (0.15,0.20,0.25) | (0.65,0.70,0.75) |
| m₂ | (0.35,0.40,0.45) | (0.35,0.40,0.45) | (0.05,0.10,0.15) | (0.05,0.10,0.15) | (0.00,0.00,0.05) |
| m₃ | (0.05,0.10,0.15) | (0.05,0.10,0.15) | (0.45,0.50,0.55) | (0.15,0.20,0.25) | (0.05,0.10,0.15) |
*(注:此表仅为SP节点示例,SG、SC、CT节点数据见原文。)*
表9 专家间的相互评价
| 评价方被评价方 | e₁ | e₂ | e₃ |
| e₁ | 1.0 | 0.5 | 0.7 |
| e₂ | 0.6 | 1.0 | 0.5 |
| e₃ | 0.8 | 0.6 | 1.0 |
通过式(19)~(25)、(27)~(28)将表8中的数据进行融合,可以得到如表10所示的结果。下面以 SP 中模糊数的中间值为例,通过式(20)计算冲突系数 K 如下:
$$K=sum_{�egin{subarray}{c}A_{i}cap A_{j}cap A_{k}=varnothing,\ A_{i},A_{j},A_{k}=I,II,III,IV,Vend{subarray}}m_{1}(A_{i})m_{2}(A_{j})m_{3}(A_{k})=0.964,5>0.95.qquad(32)$$
进一步需用式$(24)sim(25)$、(27)计算出新的基本信任分配函数和新的冲突系数。经过 3 次迭代后,利用式(28)可以得到如下结果
$$�egin{align*}sum_{�egin{subarray}{c}A_{i}cap A_{j}cap A_{k}=I\ A_{i},A_{j},A_{k}=I,,II,,,III,,,IV,,,Vend{subarray}}m_{1}(A_{i})m_{2}(A_{j})m_{3}(A_{k})\ m(I)=frac{1-K}{1-K}=&,0.145,1,end{align*}qquad(33)$$
同理,可以计算出其他4个等级分别为0.088 8、0.490 6、0.102 9、0.205 8。
表10 融合结果 (示例:SP节点)
| 等级 | I | II | III | IV | V |
| SP | (0.1046,0.1451,0.2038) | (0.0562,0.0888,0.1384) | (0.5187,0.4906,0.6383) | (0.0502,0.1029,0.1389) | (0.1370,0.2058,0.1973) |
*(注:此表仅为SP节点示例,SG、SC、CT节点数据见原文。)*
根据模糊贝叶斯理论以及表 5~9,通过式(6)~(9)可以得到 ODL 在各风险等级的平均模糊概率,下面以第 I 等级为例
$$�egin{align*} P(ODL=I)&=sum_{i=1}^5 P(ODL|SP, TR, CT)otimes P(TR|SC, SG)otimes P(SC)otimes P(SG)otimes P(SP)otimes P(CT)\
&=(0.622,5,0.692,5,0.902,2),end{align*}qquad(34)$$
再通过式(29)将其去模糊化和归一化,可以得到如表11所示的结果。由表11可知,叶节点 ODL 的依赖程度为 I 级时概率最大,为 0.698 9;依赖程度为 II~V 级时,概率逐级递减。因此,可以得出最终的总体依赖程度较低,不适合继续进行相关工作。
表11 ODL的各等级概率
| 等级 | I | II | III | IV | V |
| ODL | 0.698 9 | 0.256 9 | 0.0213 | 0.0211 | 0.0018 |
4 对比分析
为说明本文改进证据理论的特点与优势,将本文改进方法与文献[16]的改进方法以及 DS 证据理论进行对比。为更清晰地展示融合结果,以 SP 节点各等级模糊概率的中间值为例。将三名专家 $e_1$、$e_2$、$e_3$ 对 SP 节点的基本概率分配函数分别通过上述 3 种方法进行融合,得到如图4所示的结果。
如图4所示,红色为本文结果,蓝色为 DS 证据理论结果,黄色为文献[16]改进方法融合结果,普通证据理论让专家 $e_1$ 和专家 $e_3$ 的结果严重影响了专家 $e_2$ 的结果,与事实不符,所以本文与文献[16]更加有优势。本文结果同文献[16]结果相比,更加贴近每名专家自身的意见,更能突出其原本特征,所以本文比文献[16]更有优势。
5 结论
本文建立了模糊贝叶斯网络的可信性分析,并提出改进证据理论对专家的意见进行融合。改进证据理论通过主观评价和客观评价相结合的方式,影响专家给出的基本概率分配函数,再对新得到的基本概率分配函数使用证据理论进行证据融合。
本文的主要优势在于将模糊贝叶斯网络和改进证据理论应用于人类的可信性分析,以实现更精确、可靠的风险感知和控制,克服了当前可靠性分析的不确定性、模糊性、随机性、专家主观意见的冲突性和计算效率差的局限性。缺陷在于仅使用三角模糊数对概率进行模糊化,后续研究可以从模糊概率论入手,提出全新的模糊贝叶斯分析。
参考文献
[1] JAYNES E T. Probability theory: The logic of science[M]. Cambridge: Cambridge University Press, 2003.
[2] SHAFER G. A mathematical theory of evidence[M]. Princeton: Princeton University Press, 1976.
[3] BLOHLVEK R, DAUBEN J W, KLIR G J. Fuzzy logic and mathematics: A historical perspective[M]. Oxford: Oxford University Press, 2017.
[4] ZADEH L A. Fuzzy sets[J]. Information and Control, 1965, 8(3): 338-353.
[5] KHALILI S. Independent fuzzy events[J]. Journal of Mathematical Analysis and Applications, 1979, 67(2): 412-420.
[6] SMETS P. Probability of a fuzzy event: An axiomatic approach[J]. Fuzzy Sets and Systems, 1982, 7(2): 153-164.
[7] BALDWIN J F, LAWRY J, MARTIN T P. A note on the conditional probability of fuzzy subsets of a continuous domain[J]. Fuzzy Sets and Systems, 1998, 96(2): 211-222.
[8] LEE E S, LI R J. Comparison of fuzzy numbers based on the probability measure of fuzzy events[J]. Computers & Mathematics with Applications, 1988, 15(10): 887-896.
[9] MARTZ H F, WAILER R A, FICKAS E T. Bayesian reliability analysis of series systems of binomial subsystems and components[J]. Technometrics, 1988, 30(2): 143-154.
[10] ONISAWA T, KACPRZYK J. Reliability and safety analyses under fuzziness[M]. Heidelberg: Physica-Verlag, 1995.
[11] CHO H N, CHOI H H, KIM Y B. A risk assessment methodology for incorporating uncertainties using fuzzy concepts[J]. Reliability Engineering & System Safety, 2002, 78(2): 173-183.
[12] WANG K S, PO H J, HSUF S, et al. Analysis of equivalent dynamic reliability with repairs under partial information[J]. Reliability Engineering & System Safety, 2002, 76(1): 29-42.
[13] WU H C. Fuzzy reliability analysis based on closed fuzzy numbers[J]. Information Sciences, 1997, 103(1/2/3/4): 135-159.
[14] 陆莹, 李启明, 周志鹏. 基于模糊贝叶斯网络的地铁运营安全风险预测[J]. 东南大学学报(自然科学版), 2010, 40(5): 1110-1114.
[15] ZHANG L M, WU X G, QIN Y W, et al. Towards a fuzzy Bayesian network based approach for safety risk analysis of tunnel-induced pipeline damage[J]. Risk Analysis, 2016, 36(2): 278-301.
[16] PAN Y, ZHANG L M, LI Z W, et al. Improved fuzzy Bayesian network-based risk analysis with interval-valued fuzzy sets and D-S evidence theory[J]. IEEE Transactions on Fuzzy Systems, 2020, 28(9): 2063-2077.
[17] KUSHWAH A, KUMAR S, HEGDE R M. Multi-sensor data fusion methods for indoor activity recognition using temporal evidence theory[J]. Pervasive and Mobile Computing, 2015, 21: 19-29.
[18] 陆文星, 梁昌勇, 丁勇. 一种基于证据距离的客观权重确定方法[J]. 中国管理科学, 2008, 16(6): 95-99.
[19] 尹东亮, 黄晓颖, 吴艳杰, 等. 基于云模型和改进 D-S 证据理论的目标识别决策方法[J]. 航空学报, 2021, 42(12): 324768.
[20] ZIO E, BARALDI P, LIBRIZZI M, et al. A fuzzy set-based approach for modeling dependence among human errors[J]. Fuzzy Sets and Systems, 2009, 160(13): 1947-1964.
[21] LEE C C, CHIANG C, CHEN C T. An evaluation model of E-service quality by applying hierarchical fuzzy TOPSIS method[J]. International Journal of Electronic Business Management, 2012, 10(1): 38-49.
[22] BOBBIO A, PORTINALE L, MINICHINO M, et al. Improving the analysis of dependable systems by mapping fault trees into Bayesian networks[J]. Reliability Engineering & System Safety, 2001, 71(3): 249-260.
[23] LI Y F, HUANG H Z, MI J H, et al. Reliability analysis of multi-state systems with common cause failures based on Bayesian network and fuzzy probability[J]. Annals of Operations Research, 2022, 311(1): 195-209.



