摘要:为了提高Elman室内可见光位置感知模型的稳健性和定位精度,提出生物启发多特征融合学习的室内可见光位置感知方法。该方法首先对获取的可见光图像进行预处理,以确保特征提取的准确性;然后,通过将预训练的神经网络模型中不同层次的特征进行融合,构建一个位置感知特征库,从而提升特征表达能力和丰富度,以此来提高模型的位置感知精度;最后,采用蜣螂优化(DBO)算法优化Elman神经网络的拓扑结构和权重参数,以解决传统Elman神经网络在室内位置感知中容易陷入局部最优的问题,并加速收敛速度和增强泛化性能。实验结果表明:在4m×3.5m×3m的立体空间内,所提算法平均定位误差为0.21m,平均定位误差小于0.4m的概率达到91.3%,相较于Elman算法,定位精度提高了22.3%。
关键词:室内可见光位置感知;视觉成像;蜣螂优化算法;Elman神经网络
论文《生物启发多特征融合学习的室内可见光位置感知方法》发表在《光通信技术》,版权归《光通信技术》所有。本文来自网络平台,仅供参考。
0 引言
近几年,随着可见光通信(VLC)的发展,基于VLC的室内位置感知受到广泛关注[1-2]。传统的室内可见光位置感知技术主要通过采集光强信号或光图像信息来实现位置感知[3-4]。图像处理和深度学习技术的快速发展为室内可见光位置感知模型开辟了新的方向。文献[5]提出一种非调制的室内可见光定位方法,利用光学原理采集单张照片构建可重复使用的指纹库,但是该方法局限性在于位置感知过程需要朝光源拍摄。文献[6]提出一种非线性摄像机辅助接收信号强度算法,利用摄像机和光电二极管,结合视觉和强度信息实现位置感知,但是该方法在发光二极管(LED)缺少的情况下难以实现高精度定位。文献[7]提出了一种基于改进Camshift跟踪算法的高精度室内可见光定位系统,该系统可以实现高精度定位,但算法较为复杂。文献[8]通过将遗传算法(GA)与粒子群算法结合,确定Elman神经网络的初始权阈值,以提高预测精度。文献[9]提出了一种改进神经模型定位方法,采用GA-最小均方(LMS)算法优化径向基函数(RBF)神经网络的连接权值矩阵,实现了0.1m的定位精度。然而,GA的实现较为复杂,并且其中参数的选择对寻优性能有着显著的影响。基于此,本文提出一种生物启发融合多特征融合学习的室内可见光位置感知方法。
1 室内可见光位置感知方法
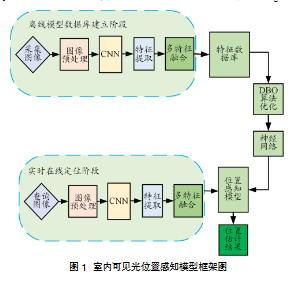
本文提出的生物启发多特征融合学习的室内可见光位置感知模型框架结构如图1所示。感知模型主要分为离线模型数据库建立阶段和实时在线定位阶段。
(图1:生物启发多特征融合学习室内可见光位置感知模型框图)
(图示说明:包含离线阶段:图像采集、预处理、ResNet50特征提取、特征融合、KPCA降维、DBO-Elman训练;在线阶段:图像采集、预处理、特征提取融合、KPCA、DBO-Elman预测)
在离线模型数据库建立阶段,本文首先采集来自不同位置的可见光图像及其对应的位置信息,并对这些图像进行预处理;然后,使用卷积神经网络(CNN)对预处理后的图像进行预训练,以提取图像在不同层次的深度特征;随后,将各卷积层提取到的深度特征进行融合,将融合后的特征作为“位置指纹”信息,用于构建指纹库。在这个过程中,融合后的图像深度特征被用作输入数据,而相应的位置坐标则作为标签。在得到位置图像融合特征后,为了降低计算复杂度,本文采用核主成分分析法(KPCA)进行数据降维。该降维方法是一种非线性降维方法,通过引入核函数将数据从原始高维空间映射到一个更低维的特征空间[14]。
位置图像通过ResNet50神经网络提取位置感知特征,并与深度特征(IFDF)融合,然后将其数字化,最终形成指纹库中的特征向量。深度特征向量表示为 I_{n}= left(I_{1},I_{2},cdots I_{n}
ight),其中 I_{n} 表示深度特征值。这样每一个位置坐标都有一组对应的深度特征向量,再使用KPCA进行数据降维,解决图像深度特征库冗余的问题。KPCA能够保留位置图像的高阶信息,使提取的特征值包含的信息更加丰富,有利于训练预测后续Elman神经网络。
在实时在线定位阶段,本文从待测图像中提取融合后的深度特征,并将其输入到之前训练并保存的神经网络中。网络会计算并输出待测点的预测坐标,从而实现精确定位。
1.1 构建基于多层融合的位置感知特征库
本文通过摄像头拍摄各个采样点的位置感知特征图像,但是由于噪声干扰容易造成图像信息丢失。本文采用对复杂图像具有较好适应性的BM3D(Block-Matching 3D)算法对采集的图像进行去噪预处理[10-11]。
位置感知特征图像经过去噪处理之后,再通过CNN提取深度特征。CNN越深,则可以捕捉结构更复杂、语义更丰富的特征,然而增加网络的深度会面临过拟合和梯度爆炸的问题。ResNet50利用残差连接有效地缓解了深度网络中的梯度消失和梯度爆炸问题[12-13],这使得模型训练更加稳定和高效。因此,本文选择ResNet50作为神经网络模型。为了使提取到的特征更加丰富,本文将低层次的特征与高层次的特征进行融合,对预处理后的图像提取融合深度特征,其融合原理框图如图2所示。
(图2:深度特征融合原理框图)
(图示说明:Layer1、Layer2、Layer4为特征层,通过Switch机制调整尺寸和通道数后进行融合)
深度特征融合的过程如下:本文采用Switch机制改变ResNet50上一层的输出通道数和尺寸,使其与下一层的特征相匹配并进行融合。例如,Layer1通过Switch处理后,其输出条件符合Layer3的输入要求,然后与Layer2相加融合进入Layer3;同样地,Layer1和 Layer2经过 Switch处理后满足 Layer4的输入条件。最后,将这3个层级的特征进行融合,输入到Layer4。这种低级与高级语义特征的结合有助于神经网络捕捉更多位置感知特征图像的信息。
1.2 DBO-Elman+IFDF算法
Elman神经网络在优化过程中容易陷入局部最优的问题,并且当初始阈值和权值选择不当时,可能导致网络过早收敛,从而限制其性能。为了解决这些问题,本文提出了DBO-Elman+IFDF算法,利用DBO算法来优化Elman神经网络与IFDF参数,以找到更优的初始阈值和权值。具体过程如图3所示,主要包括以下步骤:
1) 初始化Elman神经网络的权重和阈值,以及设定DBO算法的相关参数,包括蜣螂种群的最大进化次数、种群规模等。
2) 计算每个蜣螂个体的适应度值,并记录当前全局最优位置。其中,适应度值函数是基于实际值与预测值之间的均方误差构建的。
3) 根据蜣螂的不同行为来更新它们的位置。对于滚球蜣螂、繁殖中的蜣螂、觅食的蜣螂和小偷蜣螂,分别调整其滚动、繁殖、觅食及偷窃的行为模式[16]来实现位置更新。
4) 更新蜣螂位置后,检查是否有个体超出预设的边界。若超出,则需重新计算每个种群的适应度值;否则,更新当前最优解及其适应度值。
5) 重复执行步骤3)、步骤4),直至达到预定的最大进化次数。最终,将找到的最优参数应用到Elman模型中。
(图3:DBO优化Elman神经网络流程图)
2 实验与结果分析
本文根据光源补偿原理在三维空间顶端布置了4个LED光源。将实验区域划分成0.1m×0.1m的正方形格子,用摄像头采集每一个格子的位置感知图像信息,提取位置图像深度特征并进行特征融合,建立图像深度特征数据库。实验环境参数如表1所示。
表1 实验环境参数
参数 值
长、宽、高(单位:m) 4、3.5、3
LED数量/个 4
位置采样间隔/m 0.1
指纹点采集数/个 2952
LED功率/W 7
相机像素/pixel 1.2 imes 10^7
随机选取特征数据库中的部分数据作为训练集,剩余数据作为测试集。将图像深度特征作为神经网络的输入,坐标作为神经网络的输出。经过神经网络训练,最终得到测试点位置预测坐标。
2.1 基于DBO算法的网络训练
在Elman神经网络的配置中,训练次数设定为1000次,学习速率设为0.01。本文采用核主成分分析(KPCA)方法对不同维度的平均误差进行对比分析后,最终确定输入层、输出层和隐含层节点数分别为256个、3个和14个。
为了优化Elman神经网络的训练过程,本文采用了DBO算法,并对其基本参数进行了多次模拟调整,最终确定如下:种群规模设为20个个体,迭代次数为50次,其中滚球蜣螂(探索者)的占比设定为0.2。
本文将DBO算法与麻雀搜索算法(SSA)[17]进行了比较,两者均用于训练Elman神经网络,旨在优化初始网络的权重和阈值,得到进化曲线如图5所示。可以看出,DBO-Elman模型展示出更快的收敛速度,其适应度值在大约第9次迭代时快速下降并趋于稳定,这表明该模型能够有效避免局部极值,迅速找到全局最优解,且最终适应度值达到了约0.27,满足了定位精度要求。相比之下,SSA-Elman模型需要更多的迭代次数(约12次)才能达到稳定状态,其最终适应度值仅为0.33,显示出较低的收敛速度。因此,考虑到DBO-Elman模型在收敛速度和定位精度上的优越表现,本文选择了DBO-Elman模型作为最终方案。
(图5:DBO-Elman与SSA-Elman收敛曲线对比)
2.2 实验结果与分析
定位误差分布图如图6所示。根据分布图可知,本文所提模型在整体定位点的平均误差为0.21m,最大定位误差为0.86m,最小误差为0.04m。
不同高度平面上的定位误差分布如图7所示。对图7的数据进行统计分析可得,当高度分别为0、0.5m时,系统的平均定位误差分别为0.202m和0.223m。这表明本系统在各种高度平面上均能保持良好的定位精度,而且高度的变化对平均定位误差的影响相对较小,体现了系统具有较高的鲁棒性。另外,图7中位于实验中心区域的预测点与真实点之间的误差较小,而位于实验区域边缘的预测点与真实点之间的误差则较大。这一现象的原因在于,靠近四周的边缘区域采集到的图像特征较少,而中心区域的图像特征更为丰富。图像特征的数量和质量直接影响了系统模型的定位精度:图像特征越丰富,系统的定位精度就越高。
(图6:定位误差分布图)
(图7:不同高度平面上的定位误差分布)
为了进一步评估系统的性能,本文对比了BP神经网络算法、Elman神经网络算法、DBO-Elman神经网络算法、DBO-Elman+IFDF算法的定位误差,结果如表2所示。可以看出,本文所提出算法的定位平均误差为0.21m,其最大误差、最小误差及平均误差均低于其它3种算法。除此之外,本文所提算法的定位精度比DBO-Elman算法、Elman算法、BP算法分别提高了8.6%、22.3%、30%。
表2 4种算法定位误差比较
定位算法 最小误差/m 最大误差/m 平均误差/m
BP 0.065 1.57 0.3
Elman 0.054 1.46 0.27
DBO-Elman 0.042 1.29 0.23
DBO-Elman+IFDF 0.031 1.18 0.21
4种算法累积误差分布曲线如图8所示。可以看出,相较于DBO-Elman算法、Elman算法和BP算法,本文所提算法的定位效果的置信概率有明显提升,小于0.5m的置信概率达到96%。
(图8:4种算法累积误差分布曲线)
3 结束语
本文通过提取图像融合深度特征,同时融合DBO算法对Elman神经网络进行优化,形成一种混合室内可见光位置感知算法,改善了Elman算法初始权值阈值选择不当导致定位精度低、稳定性差的问题,提高室内定位精度。实验结果表明:本文所提算法平均定位误差为0.21m,平均定位误差小于0.4m的概率达到91.3%,相较于Elman算法,定位精度提高了22.3%。本文所提算法小于0.5m的置信概率达到96%,高于其它几种算法。
参考文献
[1] 赵黎, 韩中达, 张峰. 基于神经网络的室内可见光立体定位研究[J]. 中国激光, 2021, 48(7): 145-154.
[2] TORRES J C, MONTES A, MENDOZA S L, et al. A low-cost visible light positioning system for indoor positioning[J]. Sensors, 2020, 20(18): 5145.
[3] HAN W, WANG J, LU H, et al. Visible light indoor positioning via an iterative algorithm based on an M5 model tree[J]. Applied Optics, 2020, 59(32): 10194-10200.
[4] HONG C Y, WU Y C, LIU Y, et al. Angle-of-arrival(AOA) visible light positioning(VLP) system using solar cells with third-order regression and ridge regression algorithms[J]. IEEE Photonics Journal, 2020, 12(3): 7902605-1-7902605-8.
[5] SHI C, NIU X, LI T, et al. Exploring fast fingerprint construction algorithm for unmodulated visible light indoor localization[J]. Sensors, 2020, 20(24): 7245.
[6] BO B, BO S, NAN C, et al. A high precision positioning method based on high speed camera and visible light[C]//Optica Publishing Group. Proceedings of Asia Communications and Photonics Conference. Washington: Optica Publishing Group, 2017: M3F.1-1-M3F.1-5.
[7] MAO W, XIE H, TAN Z, et al. High precision indoor positioning method based on visible light communication using improved Camshift tracking algorithm[J]. Optics Communications, 2020, 468: 125599.
[8] WU Y H, LIU J B, ZHANG J A, et al. Short-term forecast of photovoltaic power generation output based on improved PSO-Elman neural network[J]. IOP Conference Series: Earth and Environmental Science, 2021, 675(1): 3-7.
[9] 张慧颖, 于海越, 王凯, 等. 基于 KPCA-K-means++和 GA-LMS模型的改进RBF神经网络室内可见光定位[J]. 光学学报, 2021, 41(19): 72-81.
[10] YAHYA A A, TAN J, SU B, et al. BM3D image denoising algorithm based on an adaptive filtering[J]. Multimedia Tools and Applications, 2020, 79: 20391-20427.
[11] YUAN Z, CHEN T, XING X, et al. BM3D denoising for a cluster-analysis-based multibaseline InSAR phase-unwrapping method[J]. Remote Sensing, 2022, 14(8): 1836.
[12] THECKEDATH D, SEDAMKAR R R. Detecting affect states using VGG16, ResNet50 and SE-ResNet50 networks[J]. SN Computer Science, 2020, 1: 1-7.
[13] ALNUAIM A A, ZAKARIAH M, SHASHIDHAR C, et al. Speaker gender recognition based on deep neural networks and ResNet50[J]. Wireless Communications and Mobile Computing, 2022, 2022: 1-13.
[14] LI X, JIA R, ZHANG R, et al. A KPCA-BRANN based data-driven approach to model corrosion degradation of subsea oil pipelines[J]. Reliability Engineering & System Safety, 2022, 219: 108231.
[15] 李宝玉, 张峰, 彭侠, 等. K-means+SSA-Elman网络室内可见光位置感知算法[J]. 应用光学, 2022, 43(3): 453-459.
[16] XUE J, SHEN B. Dung beetle optimizer: a new meta-heuristic algorithm for global optimization[J]. The Journal of Supercomputing, 2023, 79(7): 7305-7336.
[17] LI Z, LUO X, LIU M, et al. Wind power prediction based on EEMD-Tent-SSA-LSSVM[J]. Energy Reports, 2022, 8: 3234-3243.



