摘要
针对物联网设备在后量子时代面临的新型安全挑战,本文基于CUDA架构提出面向babyKyber算法的并行优化方案。研究聚焦该算法中多项式乘法与数论变换等核心模块,通过细粒度并行将运算拆解至GPU线程级实现计算加速,同时采用粗粒度并行构建多线程块架构以提升算法吞吐量。特别地,本文通过动态线程块配置实验探索GPU资源利用率优化路径。实验数据表明:优化后的并行方案在NVIDIA GeForce MX150平台实现千万级吞吐量,较CPU平台获得三个数量级的加速增益。该研究为后量子密码算法在资源受限物联网终端的工程化部署提供可行解决方案。
关键词:后量子密码;Kyber;GPU;babyKyber;物联网
0 概述
量子计算技术的突破性发展正深刻动摇传统公钥密码体系根基。例如,量子计算可以有效破解基于大整数因子分解和离散对数问题的公钥加密算法[1],传统计算机需要指数级时间来解决这些问题,而量子计算机可以在多项式时间内解决[2],相较传统计算机的指数级运算时间呈现出颠覆性优势。后量子密码是指能够抵抗量子计算机攻击的密码算法和协议,其可以抵御量子攻击的原因在于其基础数学难题在量子计算机上仍然保持高复杂度,即使利用量子算法也难以高效解决这些问题[3]。美国国家标准与技术研究院(NIST)主导的后量子密码标准化进程中,Kyber算法作为一种基于格的后量子密钥封装机制[4],它不仅提供了对抗量子计算攻击的能力,而且效率高,密钥尺寸小[5],已通过NIST第三轮评估认证,成为密钥封装机制的首选方案。
物联网设备在智慧城市、工业控制等场景的规模化部署,催生了百亿级终端的安全防护需求。传统密码算法在资源受限设备上的高能耗特性与量子脆弱性双重制约下,亟需构建新型安全架构。BabyKyber作为Kyber算法的轻量化变体,通过参数精简实现50%内存占用优化,同时保持MLWE问题核心安全假设,其毫秒级密钥生成速度与12.8kB/s的低带宽需求,完美契合边缘计算节点的资源约束条件。该算法已通过NIST第三轮评估认证,为物联网设备提供了可验证的量子安全防护基线。
为满足物联网设备对实时性能的需求,GPU并行计算技术提供了有力支持。GPU的高并行处理能力使其能够快速处理大量数据,这对于实时监控和自动化控制系统至关重要。通过在GPU上并行执行babyKyber算法,可以显著加快密钥生成和加密过程,提升物联网应用的实时性能。此外,GPU并行处理技术还通过降低能耗和成本,提高了物联网设备的整体运行效率和可靠性。
本文总结了后量子密码Kyber算法GPU并行的相关研究现状,重点分析了Kyber算法流程以及GPU编程模型,提出了粗细粒度结合的并行方案。基于GPU对babyKyber算法进行了并行设计,提出并实现了三种并行方案。最终验证了并行结果正确性,并进行了并行性能测试。
1 相关研究
1.1 kyber研究
后量子密码(PQC)被认为是量子时代传统密码系统的可靠替代[6],有关学者对后量子密码进行了一系列的研究。张帆等人[7]针对后量子密码的安全性进行了详细的评估,主要集中在如何通过安全编码和故障注入测试来提升密码系统的抗攻击能力。吴伟彬等人[8]则从抗侧信道攻击的角度出发,分析了利用随机化技术和干扰信号来防御时间攻击和功率分析攻击。眭晗等人[9]探讨了后量子环境中对称密钥算法面临的挑战,如密钥管理和算法的量子抗性问题。
目前,对kyber算法的研究主要包括硬件实现优化[10][11]、安全性分析与提升[12]、在特定应用场景中的可行性研究[13]等方面。李斌等[14]提出了一种针对Kyber算法的多路并行优化实现方案,通过在FPGA上进行优化设计,显著提高了算法的执行效率。Arpan Jati等[15]引入了多种侧信道攻击防护机制,提出了一种可配置的kyber硬件实现方案。
BabyKyber是基于Kyber算法的一个轻量级变体,专为物联网等资源受限的环境设计。BabyKyber通过简化一些参数和计算过程,为物联网提供了一个既安全又高效的加密方案,能够适应各种设备和应用场景,确保数据在传输和处理过程中的安全,同时对设备的性能和运行效率影响较小。这使得它成为物联网安全通信中一个非常有价值的工具。Charu Awasthi等[16]通过使用babyKyber加密算法,在动态物联网基础设施中保护物联网设备对设备的通信。
1.2 基于GPU的后量子算法并行研究
GPU可以用于加速后量子密码算法的并行计算,提高其性能,基于GPU的后量子算法并行研究涉及算法设计、异构计算平台利用、硬件加速等多个方面。董建阔等[17]利用GPU的大规模并行处理能力,开发适合于量子抵抗算法的并行架构,以及如何有效地将这些算法映射到多核心GPU上以优化性能。穆健健等[18]利用CUDA进行并行加速运算,重点改进了数据传输和处理流程,减少了加密过程中的时间延迟,提升了算法整体的吞吐量。An SW等[19]对LWE算法在内存访问和并行执行策略上进行了改进,以减少内存占用和计算延迟。此外,Choi S等[20]提出了一种高效的部分并行NTT处理器。他们通过优化电路结构和资源分配,不仅提高了处理器的效率和能效比,而且使其在硬件实现中更为高效,尤其是在低功耗环境中的应用表现突出。
此外,也有相关学者对kyber算法的GPU并行进行了研究。L Wan等人[21]提出使用AI加速器加速多项式乘法,使用tensor core来优化NTT,实现了加速效果,但对于AI加速器在不同场景下的适用性和通用性的分析还有所欠缺。Naina Gupta等[22]提出从优化任务划分、减少任务划分、使用内存合并等方式对kyber算法进行了CUDA实现,但实现过程中并没有完全GPU并行化。Xinyi Ji等人[23]基于GPU提出了一种基于核融合的栅格后量子实现架构,减少了全局访问次数,同时针对NTT提出切片层合并的方法来进行加速,在算法实现上进行了优化。Wai-Kong Lee等人[24]提出在物联网应用中加速kyber算法,使用细粒度并行的方法在GPU上并行NTT,并通过合理内存分配的方法进行优化,但除了加密解密之外的模块仍需要在CPU上完成。
目前的研究主要是针对kyber算法的某个关键部件进行并行,而没有对kyber整个算法进行GPU并行。为了更好地利用GPU环境中的并行计算优势,本文对babyKyber算法的计算流程进行了分析,提出了一种基于GPU的babyKyber算法整体并行加速方案,实现密钥生成、加密、解密、验证全流程GPU并行化,并且基于babyKyber算法进行了实验验证。
2 后量子密码babyKyber算法和GPU并行技术
2.1 后量子密码babyKyber算法简介
BabyKyber是Kyber算法的一个简化版本。在物联网(IoT)领域中,BabyKyber算法的应用主要集中在提供强化的安全性和适应资源受限环境的能力上。物联网设备往往受限于处理能力、存储空间和能耗,因此需要特别优化的加密算法来保障数据安全。BabyKyber因其参数较小、运算需求相对较低,在身份验证、数据完整性验证、能效优化等方面发挥作用。
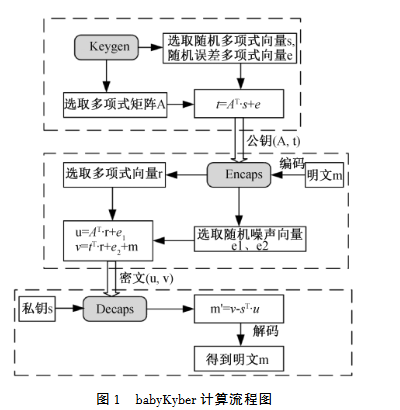
在babyKyber中,为了保持算法的轻量级,多项式的度数通常较低,如设置为3或4,简化了多项式乘法和其他相关运算模数q是定义多项式运算中系数的基础,对于babyKyber,模数被设定得较小以简化计算,比较典型的选择是17或者其他较小的素数,这有助于减少计算复杂性并提高运算速度。要求私钥s和随机噪声向量e都是由小系数的多项式组成的向量。故本文将的n值设定为4,q设定为17,设定的A、s、e的具体数值如(1)(2)(3)。此外,由于babyKyber算法也涉及多项式加法和乘法操作,相乘过程中多项式的次数会累加,为防止超出n值,这些多项式需要进行模运算。本文选定多项式 (f=x^{4}+1) 作为模运算的基础以确保所有多项式的次数都会小于 (x^{4}) 计算过程中所有的系数都是模4运算所有的多项式都是模f运算。BabyKyber的计算流程如图1所示。
2.2 GPU编程模型与并行设计
与CPU的复杂控制单元相比,GPU采用简化的逻辑控制架构,其运算单元占比高达90%,更适合处理大规模数据并行任务而非复杂串行计算。GPU通过超长流水线设计和海量计算单元实现高吞吐量,其线程组织以线程块为单元,每个块最多容纳1024个线程,并由32线程组成的线程束作为调度基础单元,所有线程束执行相同指令流但操作不同数据。这种SIMT(单指令多线程)架构使得GPU在并行计算中具备数量级性能优势,尤其在处理图像渲染、矩阵运算等可分解任务时表现突出。
GPU并行技术主要分为粗粒度并行和细粒度并行两种。细粒度并行将大任务细分为众多微小子任务(线程)并行执行,尤其适用于单个任务内部的并行计算,常见于GPU上单线程处理单个数据操作,如矩阵乘法、多项式乘法等计算密集型任务。该方式下,任务先分解为较大独立模块,再进一步细化至微小任务单元,由各自线程执行,实现任务块的多线程并行。相比之下,粗粒度并行在更高层次划分任务,将大任务直接分配给线程块,每个线程块负责完整任务,内部不再细分。此方式适合多线程批量处理,GPU能将大任务分配至不同线程块并行执行,任务间通信依赖全局内存。在加密或解密多条消息时,可将每条消息视为独立任务并行处理,利用粗粒度并行大幅提升处理效率。粗粒度并行增强多任务场景下算法吞吐量,而细粒度并行则专注于提升单个任务计算速度。结合两者,GPU能在不同层次保持高负载运行,最大化并行能力和资源利用率,是GPU并行计算中提升整体性能和资源利用的关键。
尽管GPU-CPU协同并行能加速后量子算法部分组件,提升性能,但因其无法同时处理多个完整算法,加速潜力受限。为克服此局限,本文提出GPU并行实现方法:将GPU线程分组(线程块),组内通过细粒度并行处理同一算法不同部分,组间则通过粗粒度并行同时执行多个完整后量子算法。此方法不仅大幅提升算法执行速度,还实现GPU资源全面高效利用,进一步增强加速效果。
- 批次配置:<<>>
- 核心逻辑:
1. 粗粒度并行:不同线程块同时执行完整算法,每个线程块开启1条线程
2. 细粒度并行:线程块内部开启多个线程,并行处理算法单个部件的不同分支
3. 线程块配置:可支持满线程块并行(所有线程利用)或半线程块并行(部分线程利用)
通常,单个线程块中的线程数量由算法部件中占用线程数量最多的那个决定,以确保所有部件都能得到足够的计算资源。而线程块的数量则由需要同时运行的算法个数决定,这有助于最大化GPU的并行处理能力。一般情况下,开启的线程块越多,加速效果越明显,但这也受到GPU可用线程总数的限制。因此,在实际应用中,我们需要根据GPU的硬件资源和算法的具体需求来合理配置线程块和线程的数量,以达到最佳的加速效果。
3 基于GPU的babyKyber算法并行设计
多项式运算(矩阵乘法)是babyKyber算法的重要部件,同时也是最耗时的部件。在多项式相乘中,每个系数的计算过程是将两个多项式中对应项的系数相乘,并累加得到新多项式中相应项的系数例如若有两个多项式 (A(x)=a_{0}+a_{1} x+a_{2} x^{2}) 和 (B(x)=b_{0}+b_{1} x+b_{2} x^{2}),它们的乘积C(x)的系数cᵢ由以下公式给出:(c_{k}=sum_{i=0}^{k} a_{i} ×b_{k-i}),这意味着每个系数cₖ都是通过所有可能组合aᵢ×bₖ₋ᵢ的和得出的。BabyKyber算法中,多项式乘法部分属于计算密集型的任务,具有细粒度并行意义,其余部分涉及线性计算,适合粗粒度并行。对此,本文提出了粗粒度并行、粗细粒度结合并行两种方案。
3.1 粗粒度并行
粗粒度并行本质上是将babyKyber算法放在一个线程中串行实现,允许多个线程同时执行多个算法。大多数数据都存储在全局内存中,例如S、A、e、t、u、v等,使用cuda.device_array分配,并通过cuda.to_device和copy_to_host实现主机与设备之间的数据传输。一次性给每个线程分配一整套密钥、多项式、向量等,线程之间几乎无共享依赖,最大化地利用GPU的并行能力。每个线程对自己的数据独立处理,n(总线程数)决定了分配的数组大小,由于每个线程都能完成自己那份全部计算任务,这种方式对于批量处理非常高效,避免了线程间数据依赖的复杂同步。
3.2 粗细粒度结合并行
babyKyber中多项式最高次数为3次的多项式,故两个多项式乘积的最高次项为6次。因此,在粗粒度并行的基础上,采用细粒度的并行策略,以7个线程构成一个线程块,这7个线程分别计算从0次到6次的多项式系数,同时启动n个线程块执行相同的核函数,每个线程块独立处理一组数据,其数量依实际需求而定。线程块内部,线程进一步细分任务,各自负责算法中的小部分计算。在CUDA中,blockIdx标识线程块,其总数对应需一次性计算的算法个数;而threadIdx则唯一标识线程块内的各个线程。
如算法4所示,计算过程中,7个线程同步工作,并将各自结果存储在中间变量m7[i]中。设x[i]、y[i]分别为两个相乘多项式i次项的系数,z[i]为乘积多项式的系数。具体而言,当threadIdx为0至6时,依次计算乘积中x的常数项、一次项直至六次项的系数。
先前的设计中一个线程块中只有7个线程,但当要处理的算法实例数量不足够多时,GPU的大多数资源可能会出现占用不够的状况。为避免这种情况导致吞吐率下降,本文又设计了另外一种方案。由于一个线程块最多有1024个线程,而细粒度并行要求一个算法占用7个线程,所以将线程块内线程数设置成1022。将这1022个线程分成146组,每7个线程一组,当需要同时计算146个babyKyber算法时,只需要开一个线程块,而不是146个。这样可以在GPU硬件层面占据更多SM、更多线程束(warp),让GPU中更多的潜在并行度被激活。Block数减少,但单块的线程数增多,对GPU的调度更友好,尤其在大规模并行场景下可以减少Kernel启动开销或线程块切换开销。
4 实验验证
4.1 正确性验证
首先,根据所选数值计算预期的输出结果。根据(1)(2)(3)可以得到公钥t:
使用公钥进行加密得到密文(u, v):
解密时使用私钥对密文(u, v)进行解密先计算一个有噪声的结果mₙ:
判断每个系数到0(或q)、q/2(即11)的距离,离0(或q)更近则记为0,反之则记为1。最后还原得到明文m_b:
其次,在CUDA环境中运行并行编程结果,打印输出的A、s、t、u、v、m值。与预计算的值相比较,两者数据一致,说明实际计算结果与理论结果一致。
然后,为进一步验证正确性,取不同的输入值进行计算。开10个线程块,每个线程块分别输入10个不同的m值,并行计算得到输出值,比较输出的m_b值与输入的m值,10组数据中二者数值皆一致,说明在不同的输入值时,并行运算结果均正确,说明并行结果正确。
|
4.2 并行性能测试
在本小节中,我们提出并讨论了所有提出的babyKyber算法的并行实现技术的实验结果。选择Windows11/CUDA12.3/python3.9/numba 0.55.1/Intel(R)Core(TM)i5-8250U CPU@1.60GHz/NVIDIA GeForce MX150作为实验环境,对babyKyber算法在CPU、GPU平台的实现效率进行了测试,同时也报告了不同批大小的babyKyber运行时的吞吐率,范围从10000到1000000次。算法代码通过Numba和CUDA编译运行。针对前面设计的三种不同的GPU并行方案,分别测试其在babyKyber算法的密钥生成、加密和解密阶段的吞吐率,每次实验重复三次取平均值,以减少随机波动的影响。吞吐率的计算规则是吞吐率=任务数/执行时间(秒),加速比的计算公式是加速比=GPU吞吐率/CPU吞吐率。
为了体现GPU的并行计算优势,本文需要对比GPU相对于CPU的加速比。首先将babyKyber算法写入CPU,计算不同批大小的babyKyber算法在GPU中的吞吐率,由于CPU不具有并行能力,算法在CPU里是串行计算,吞吐率与计算数量无关,故只用测试某一个批次的babyKyber算法在CPU中的吞吐率即可,基于CPU的babyKyber算法实现的吞吐率如表1所示。
为了比较不同并行方案的吞吐率,我们分别测量了它们在10000个、100000个、1000000个babyKyber实例上的计算时间,并计算其吞吐率、GPU-CPU加速比。表2、3、4分别展示了粗粒度并行、粗细粒度结合并行(thread_per_block=7)、粗细粒度结合并行(thread_per_block=1022)的实验结果:
图7、8、9展示了随着数据规模的增加,不同并行方案的吞吐率变化对比。其中横轴表示计算的babyKyber算法个数,纵轴表示相对应的吞吐率(单位为:次/秒)。为了方便表示,“模式一”代表粗粒度并行,“模式二”代表每个线程块分配7个线程的粗细粒度结合并行,“模式三”代表每个线程块分配1022个线程的粗细粒度结合并行。
由以上测试数据可以得出以下几条结论:
1. 完全粗粒度并行方案在数据量为10000条时,实现了密钥生成1000000次/s,加密625000次/s,解密1666666次/s的吞吐率,实现了密钥生成83,加密75,解密63的GPU-CPU加速比。在数据量增加时,粗粒度并行的吞吐率呈缓慢上升的趋势,但由于线程块限制,最终趋于平缓,并没有达到完美的加速效果。
2. 粗细粒度结合并行方案(thread_per_block=7)在数据量为10000条时实现了密钥生成5000000次/s,加密2500000次/s,解密5000000次/s的吞吐率,实现了密钥生成415,加密300,解密190的GPU-CPU加速比。这种方案在吞吐率上优于粗粒度并行方案,但由于线程块的利用率不足,在数据量增加时只实现了吞吐率的小幅提升,没有达到完美的加速效果。
3. 粗细粒度结合并行方案(thread_per_block=1022)在数据量为10000条时实现了密钥生成10000000次/s,加密5000000次/s,解密10000000次/s的吞吐率,实现了密钥生成830,加密600,解密380的GPU-CPU加速比。这种方案在吞吐率上相比其他两种方案有显著提高,在加速比上也明显优于其他两种方案。在大数据规模下,这种方案实现了千级GPU-CPU加速比,相对于粗粒度并行也实现了5倍余的加速。
5 总结
鉴于当前基于GPU的Kyber算法实现仅限于其组件级别的并行处理,且该过程中需依赖CPU进行调度,进而引入了额外的时延,本文提出了一种创新的Kyber算法整体GPU并行加速方案。基于BabyKyber算法,我们最终实现了三种GPU并行模式:粗粒度并行、以及两种不同配置的粗细粒度结合并行(其中线程块内线程数分别设为7和1022)。实验不仅验证了Kyber算法整体GPU并行加速方案的可行性,还深入探索了不同并行策略的效果。实验结果表明,在三种不同的数据量下,采用粗细粒度结合并行策略(线程块内线程数为1022)的性能均优于其他两种模式,特别是在处理大规模数据时,其吞吐率和加速比的提升尤为显著。通过增加线程块内的线程数量并精心组织线程间的协作,我们成功实现了GPU资源的高效利用,为后量子密码算法的高效并行化探索提供了一条重要路径。
此外,本研究还提升了物联网领域利用BabyKyber算法批量处理大数据的能力,实现了GPU资源的高效利用。相较于传统的CPU处理或分散式处理方案,该策略不仅减少了能源消耗,还有效降低了运行成本,为物联网应用的安全性和效率带来了双重提升。这一成果为后量子密码算法在物联网领域的应用提供了有力的技术支撑,并展示了GPU在高性能计算领域的巨大潜力。
参考文献
[1] Shor,P.W.Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer[J]. SIAM review, 1999,303-332.
[2] 段孟环,李志强,郭玲玲.量子近似优化算法在最大独立集中的应用[J].Application Research of Computers/Jisuanji Yingyong Yanjiu,2023,40(9).
[3] 王潮,姚皓南等.量子计算密码攻击进展[J].计算机学报,2020,第43卷,第9期.
[4] JBos et al.CRYSTALS-Kyber:A CCA-Secure Module-Lattice-Based KEM[J].IEEE European Symposium on Security and Privacy, 2018,353-367.
[5] Alagic G,Alperin-Sheriff J,Apon D,et al.Status report on the second round of the NIST post-quantum cryptography standardization process[J]. US Department of Commerce, NIST,2020,2:69.
[6] 刘冬生,李奥博,胡昂,陆家昊,黄天泽,杨朔,李翔,张嘉明.后量子密码算法与芯片设计研究进展[J].科技导报,2024,42(2):20-30.
[7] 张帆,杨博麟.如何正确和安全地开展后量子密码算法的相关实现(英文)[J]. Journal of Cryptologic Research,2023,10(3):650.
[8] 吴伟彬,刘哲,杨昊,张吉鹏.后量子密码算法的侧信道攻击与防御综述[J].软件学报,2021:1165-1185.
[9] W.Guo,S.Li,L.Kong.An Efficient Implementation of KYBER[J].IEEE Transactions on Circuits and Systems II:Express Briefs, 2022:1562-1566.
[10] M Bisheh-Niasar,R Azarderakhsh,M Mozafari-Kermani.Instruction-Set Accelerated Implementation of CRYSTALS-Kyber. IEEE Transactions on Circuits and Systems I:Regular Papers,2021:4648-4659.
[11] Arpan Jati,Naina Gupta,et al.A Configurable CRYSTALS-Kyber Hardware Implementation with Side-Channel Protection[J].ACM Trans.2024,25 pages.
[12] Backlund L,Ngo K,Gärtner J,et al.Secret key recovery attack on masked and shuffled implementations of CRYSTALS-Kyber and Saber[C].Cham:Springer Nature Switzerland, 2023:159-177.
[13] Da Costa VLR,Camponogara Â,López J,et al. The feasibility of the crystals-kyber scheme for smart metering systems[J].IEEE Access,2022,10:131303-131317.
[14] 李斌,陈晓杰,冯峰,周清雷.后量子密码 CRYSTALS-Kyber的FPGA多路并行优化实现[J].通信学报,2022,43(2):196-207.
[15] Jati A,Gupta N,Chattopadhyay A,et al.A configurable CRYSTALS-Kyber hardware implementation with side-channel protection[J]. ACM Transactions on Embedded Computing Systems,2024,23(2):1-25.
[16] Kwala AK,Kant S,Mishra A.Comparative analysis of lattice-based cryptographic schemes for secure IoT communications[J].Discover Internet of Things,2024,4(1):13.
[17] 董建阔,黄跃花,付宇笙,等.基于异构多核心GPU的高性能密码计算技术研究进展[J].软件学报,2024:1-27.
[18] 穆健健,郭大波,马识途,等.基于CPU/GPU异构平台的连续变量量子密钥分发多维数据协调[J].Laser&Optoelectronics Progress,2019,56(15):152702.
[19] An SW,Seo SC.Efficient parallel implementations of LWE-based post-quantum cryptosystems on graphics processing units[J]. Mathematics,2020,8(10):1781.
[20] Choi S,Shin Y,Lim K,et al.Efficient Partially-parallel NTT Processor for Lattice-based Post-quantum Cryptography[J]. JOURNAL OF SEMICONDUCTOR TECHNOLOGY AND SCIENCE,2022,22(6):459-474.
[21] Wan L,Zheng F,Fan G,et al. A novel high-performance implementation of CRYSTALS-Kyber with AI accelerator[C]//European Symposium on Research in Computer Security.Cham:Springer Nature Switzerland, 2022:514-534.
[22] Gupta N,Jati A,Chauhan AK,et al.Pqc acceleration using gpus:Frodokem,newhope,and kyber[J].IEEE Transactions on Parallel and Distributed Systems,2020,32(3):575586.
[23] Ji X,Dong J,Deng T,et al.HI-Kyber:A novel high-performance implementation scheme of Kyber based on GPU[J].IEEE Transactions on Parallel and Distributed Systems,2024.
[24] Lee WK,Hwang SO.High throughput implementation of post-quantum key encapsulation and decapsulation on GPU for Internet of Things applications[J].IEEE Transactions on Services Computing,2021,15(6):3275 -3288.



